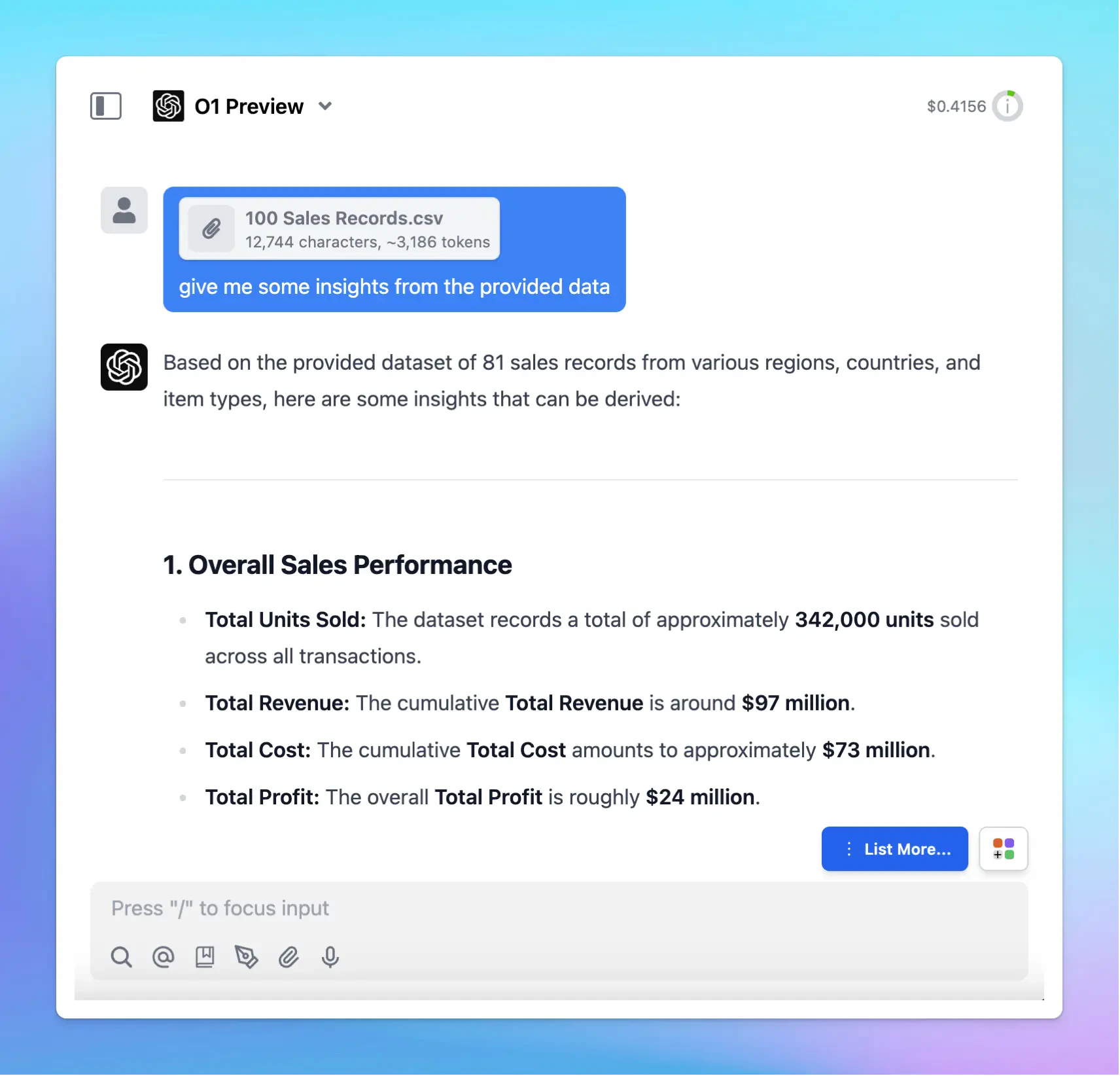
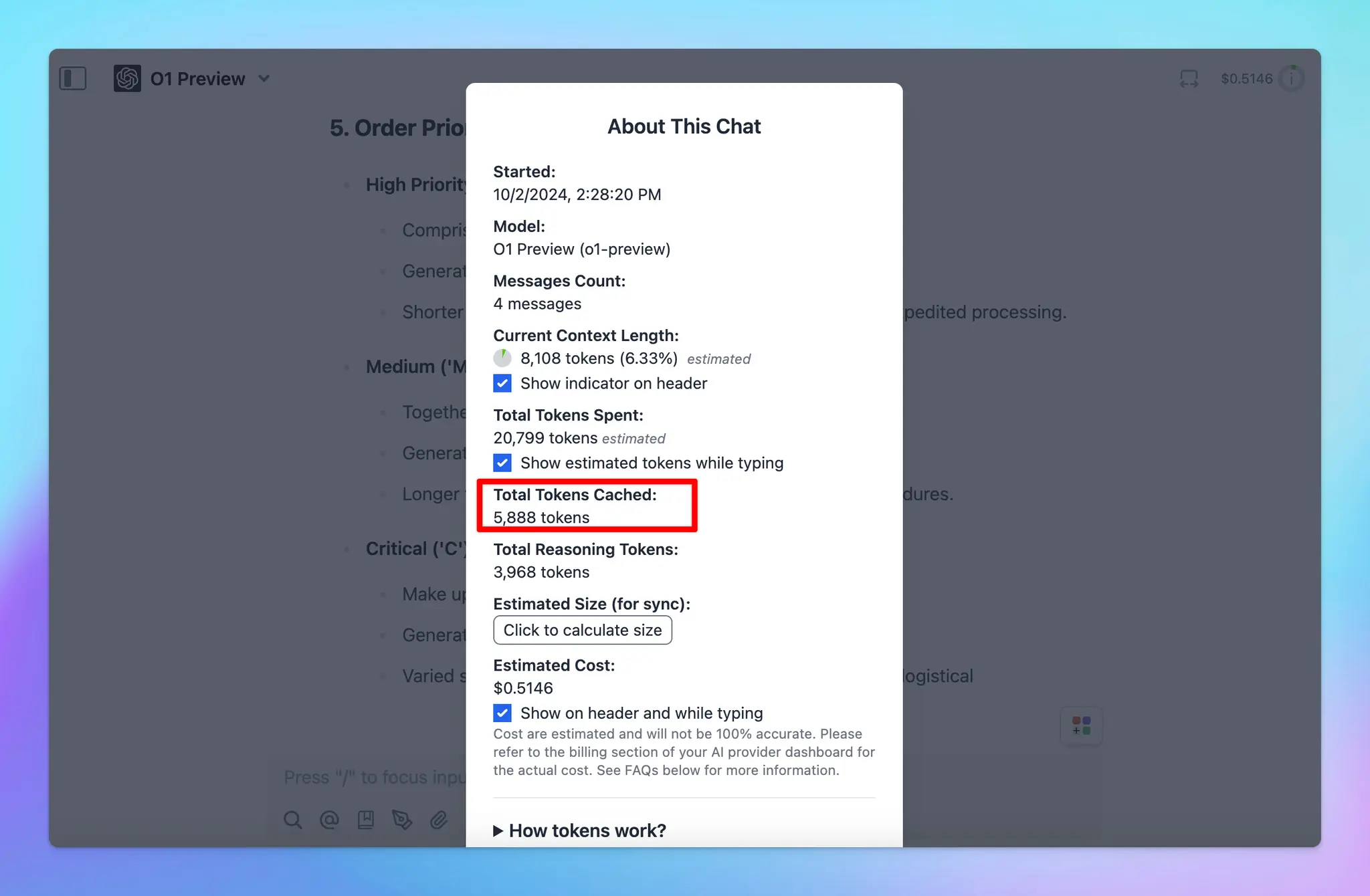
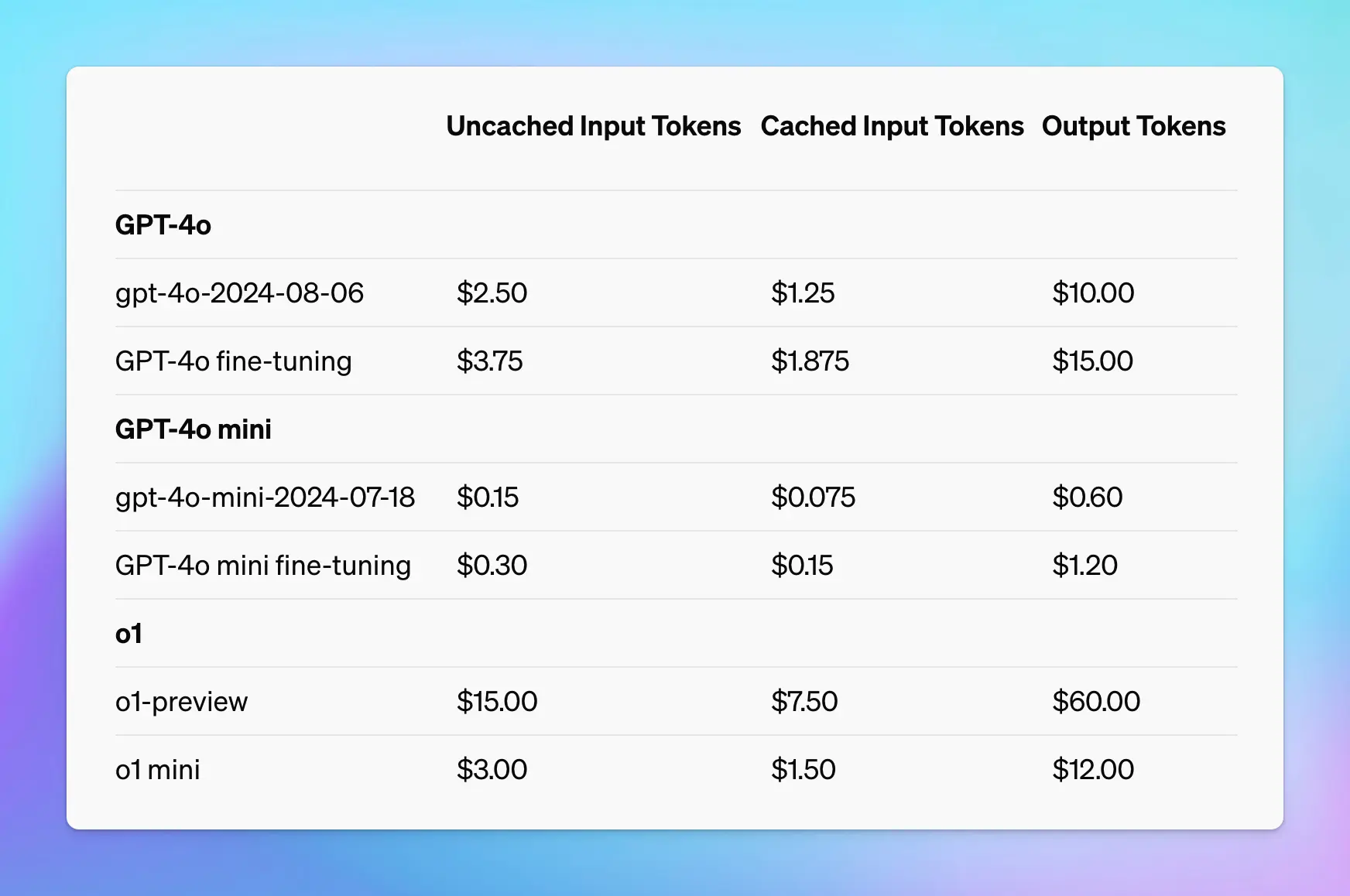
- Supported on the latest version of GPT-4o, GPT-4o mini, o1-preview, o1-mini.
- You can get a 50% discount on input tokens when using cached prompts for OpenAI models. Plus, it can also reduce up to 80% in latency!
🏁 How it works
You don’t need to do anything to enable OpenAI Prompt Caching - it will be automatically applied when using supported models. Learn more on https://docs.typingmind.com/prompts/automatic-prompt-caching-(claude-and-openai)